Coding Agents: Increase the autonomy slider¶
July 2025
AI coding agents like Claude Code, Cursor, and Gemini CLI have galvanized excitement in the software engineering world. And for good reason: so many of the mundane coding tasks are now completely automated, leaving engineers to think about higher level architecture & design, the fun parts of building products.
Using Claude Code more has made me happier - I find flow states that feel more like product management than coding. Coding is the boring part (to me).
This post explores some of my techniques for staying in this flow state as much as possible. In his Software 3.0 talk, Karpathy describes what he calls the "autonomy slider"—you can be "mostly in charge" with small edits, or slide toward full autonomous operations. Other than the usual tricks like good prompting, plan mode, etc, I think the most important mindset is about enabling agents to self-verify. Self-verification happens at all scales: the macro (the entire product) and the micro (small tools to assist in building features).
If you want to see code, see this project where I built a Databricks App that has a UI with a LangGraph Agent, monitored with MLflow 3.0. This post will focus on Claude Code, but these tricks apply to Cursor, Gemini, and other AI coding tools.
The orchestra¶
Imagine we're in an orchestra where I'm the conductor, Claude is the musician. Types, tests, and docs keep our instruments in tune. This post explores how to teach Claude to hear—to build self-verification loops that let it catch and fix its own mistakes while playing.
The Naive Way (Human as Bottleneck):
The Self-Verification Way:
Tuning Instruments: Choosing the Right Stack¶
Just like quality instruments help musicians play better, the right tools help AI agents code better. The best ones are fast, have guardrails, and provide rich type information. This is my preferred stack for Python backend + TypeScript frontend projects (though these ideas work with any tools):
Python tooling¶
- uv, for 10-100x faster package management
- Ruff, for lightning-fast linting and formatting
- ty, for extremely fast type checking
(I just use whatever Charlie Marsh builds at this point.)
Backend framework¶
FastAPI. The automatic OpenAPI docs at /docs are clutch—Claude can read them to understand your API without me copy-pasting endpoint definitions.
Frontend¶
- Vite, for lightning-fast dev server with hot module replacement
- Bun, for all-in-one JavaScript tooling
- React, because LLMs are good at it (I prefer Svelte, but LLMs have trained on far less Svelte code)
- shadcn/ui, for copy-paste components with full code ownership
Python ⟷ Frontend bridge¶
OpenAPI code generation. FastAPI schemas → OpenAPI spec → TypeScript types and client code. Change a Python type? TypeScript updates automatically. No more "oh I forgot to update the frontend types" bugs.
All these tools create tight feedback loops. Claude writes code, the tooling immediately tells Claude if something's wrong, Claude fixes it. No waiting for me to notice.
Now that our instruments are tuned, let's teach Claude to hear.
Ear Training: Self-Verification¶
Every time I build something now, I ask myself two questions:
- What am I building?
- How will Claude know if it worked?
It's easier for LLMs to verify than to generate. Just like how anyone can hear when a note is off-key, but playing in tune is hard. So I teach Claude to be its own critic.
Basic Self-Verification¶
The setup below is a simple Python webserver with a React frontend to demonstrate how I orchestrate self-verification loops.
Hot reload devserver¶
A hot-reloading devserver that rebuilds instantly dramatically speeds up inner loop development. The setup reloads both FastAPI (python changes), Typescript, and React. There's also logic to automatically rebuild Typescript hooks when the FastAPI API changes.
This setup allows Claude to make changes and instantly debug itself. If your setup is slow, it's worth spending time making the hot-reloading fast.
#!/bin/bash
# Start everything in parallel
uv run uvicorn server.main:app --reload &
bun vite --host &
# Auto-regenerate TypeScript client when Python changes
uv run watchmedo shell-command \
--patterns="*.py" \
--command='uv run python make_openapi.py | npx openapi-typescript-codegen --input stdin --output client/api' \
src/server &
In CLAUDE.md, I tell it to run with: nohup ./watch.sh > watch.log 2>&1 &.
Claude can read the logs in the watch.log, and kill the server with pkill.
All of these are remembered in CLAUDE.md.
Lint & auto-format¶
To reduce the amount of work the LLMs have to do, I try to make my linting & formatting do as much as they can. They're typically faster, and free up tokens to fix more complex issues.
I add this to the memory to do this automatically between some changes. You can also use Claude Hooks if you want to do this without the LLM making that decision.
Debugging complex behavior¶
Often complex bugs arise, either with performance, or interaction between two non-trivial systems. I often will just ask Claude to instrument the code to debug the issues. Since it can read all the logs from the devserver, we've set up a self-verification loop to fix these types of issues.
No fancy profilers. Just:
Claude Scratchpad¶
I give Claude a claude_scripts/ folder for throwaway scripts. Claude loves to create test scripts, sometimes inlining them. I prefer to let Claude write them because if something works, it acts as a memory for the future when I integrate it into the larger system.
I usually tell Claude to use uv inline dependencies to keep scripts hermetic instead of adding dependencies to the project unless they're needed by the actual system. This is also added to CLAUDE.md.
# /// script
# requires-python = ">=3.11"
# dependencies = ["requests", "pandas"]
# ///
import requests
import pandas as pd
# Quick analysis script Claude wrote
response = requests.get("http://localhost:8000/metrics")
df = pd.DataFrame(response.json())
print(df.describe())
API Self-Testing¶
I try to keep verification loops as tight as possible. If Claude needs to debug a FastAPI endpoint, it's better to have Claude curl the endpoint directly, instead of debugging it through the UI, for example.
I usually keep CLAUDE.md in sync with the OpenAPI spec that FastAPI produces. FastAPI gives a nice /docs endpoint and an /openapi.json endpoint where the API is well defined. I'll periodically tell Claude to read it and update the memory.
## API Endpoints
- API docs: http://localhost:8000/docs
- OpenAPI spec: `curl http://localhost:8000/openapi.json`
## Common endpoints
- Health check: `curl http://localhost:8000/health`
- Create item: `curl -X POST http://localhost:8000/items -d '{"name": "test"}'`
- List items: `curl http://localhost:8000/items`
Browser Automation with Playwright¶
Claude can take screenshots and see what it built. Install with:
Now Claude can click buttons, take screenshots, verify the UI actually works. Way better than me describing what's broken.(If you want to automatically login with Playwright, I made this repo which will automatically copy cookies before opening Playwright.)
Deployment¶
In my Databricks app, the deployment process has built-in verification:
# Deploy command triggers deployment
databricks apps deploy
# Check deployment logs
curl https://my-app.databricks.com/logz
# Verify deployment succeeded
curl https://my-app.databricks.com/health
Claude follows this pattern:
- Run
deploycommand - Wait for deployment to complete
- Check
/logzendpoint for errors - If errors found → fix and redeploy
- If success → verify the app is responding
Crescendo: The Next Movement¶
Once we have the basics down, here's where it gets interesting. These are some examples I thought were cool when in the self-verification loop mindset:
Example 1: SQL Stitching in JavaScript¶
I was recently working on an app where Javascript stitches together SQL queries (don't judge me: it was the simplest way to prototype something).
I wanted to make a tighter verification loop when Claude was writing Javascript that generated SQL, without having to execute the app end to end.
To do that, I had Claude write a simple Python script that would execute any SQL query (against a Databricks SQL warehouse), and in its memory I would have Claude always use the script whenever making changes to SQL in Javascript. That way Claude could always verify itself as Databricks SQL is slightly different than most other dialects.
// In the browser - hard to test
const getTraceAnalytics = (experimentId, startDate) => `
SELECT
date_trunc('hour', start_time) as hour,
COUNT(DISTINCT trace_id) as total_traces,
AVG(total_tokens) as avg_tokens,
SUM(CASE WHEN status = 'ERROR' THEN 1 ELSE 0 END) as error_count,
PERCENTILE_CONT(0.95) WITHIN GROUP (ORDER BY latency_ms) as p95_latency
FROM mlflow.traces
WHERE experiment_id = '${experimentId}'
AND start_time >= '${startDate}'
GROUP BY 1
ORDER BY 1
`;
# Claude's validation script
import re
from databricks import sql
def test_mlflow_queries(js_file):
# Extract SQL from template literals
with open(js_file) as f:
content = f.read()
sql_templates = re.findall(r'`\s*(SELECT[\s\S]*?)`', content)
for template in sql_templates:
# Replace ${var} with test values appropriate for MLflow
test_sql = template.replace('${experimentId}', "'test-exp-123'")
test_sql = test_sql.replace('${startDate}', "'2024-01-01'")
# Execute against Databricks and show results
with sql.connect(...) as conn:
cursor = conn.cursor()
cursor.execute(test_sql)
# Print results as table
rows = cursor.fetchall()
columns = [desc[0] for desc in cursor.description]
print(f"\n{' | '.join(columns)}")
print('-' * 80)
for row in rows[:5]: # Show first 5 rows
print(' | '.join(str(val) for val in row))
Example 2: Automated Purchasing of Bandcamp Songs¶
I am working on a side project where I automate purchase from Bandcamp, a website for purchasing songs directly from artists.
This required writing a browser automation tool that could purchase a song on behalf of a user, clicking through a complex UI workflow.
The trick here is an iterative self-verification loop: Claude slowly builds out the scraper. At the end of the checkout script, it dumps out HTML and a screenshot. Claude Code knows my goal: get to the final "purchase" screen, so it can choose what the next step is. Of course, I was often guiding it, but with plain English about what to click, and sometimes that it needed to wait for a few seconds.
Demonstration of the script being built:
Iteration 1:
# Just navigate and see what's there
await page.goto("https://gloopy1.bandcamp.com/track/from-the-start")
await page.screenshot(path="debug_1_initial.png")
with open("debug_1_initial.html", "w") as f:
f.write(await page.content())
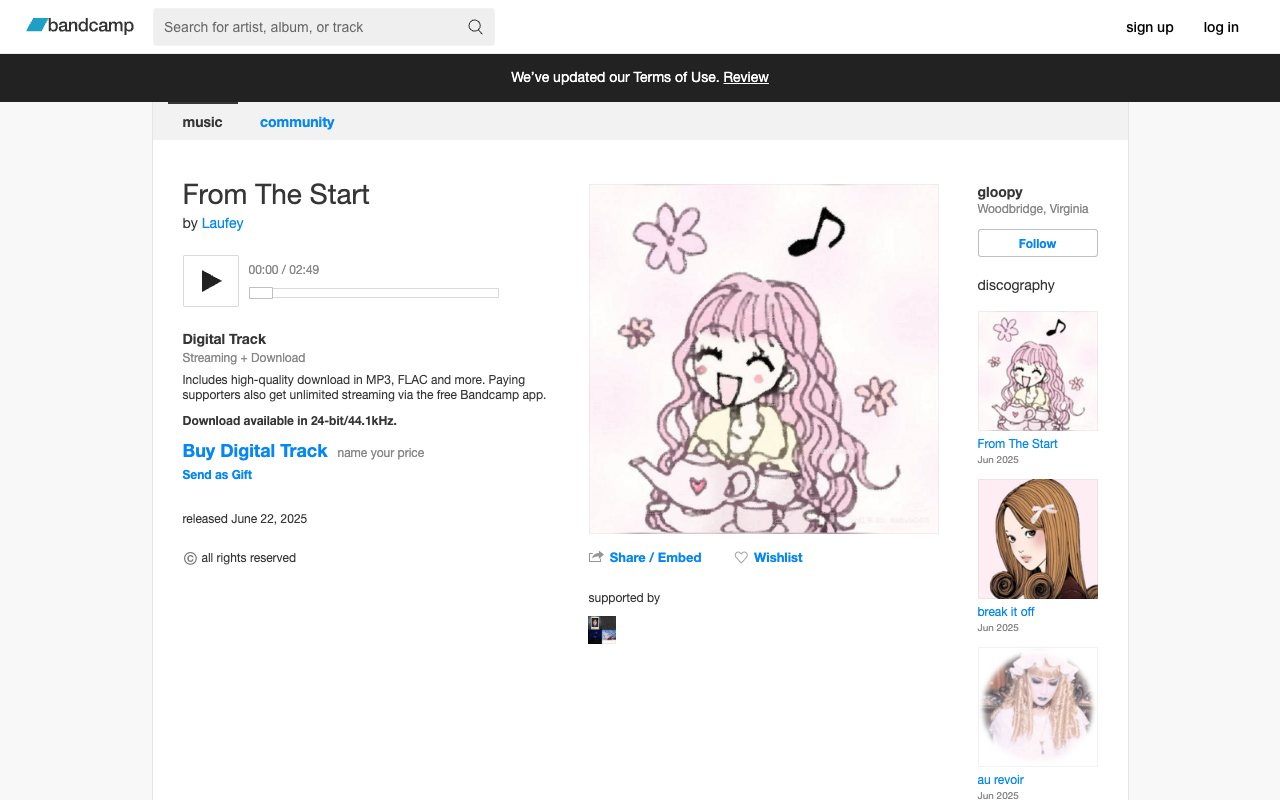
Claude sees the page, finds the "Buy Digital Track" button. I confirm, we move on.
Iteration 2:
# Navigate and click the buy button
await page.goto("https://gloopy1.bandcamp.com/track/from-the-start")
await page.screenshot(path="debug_1_initial.png")
await page.click("button:has-text('Buy Digital Track')")
await page.screenshot(path="debug_2_after_click.png")
with open("debug_2_after_click.html", "w") as f:
f.write(await page.content())
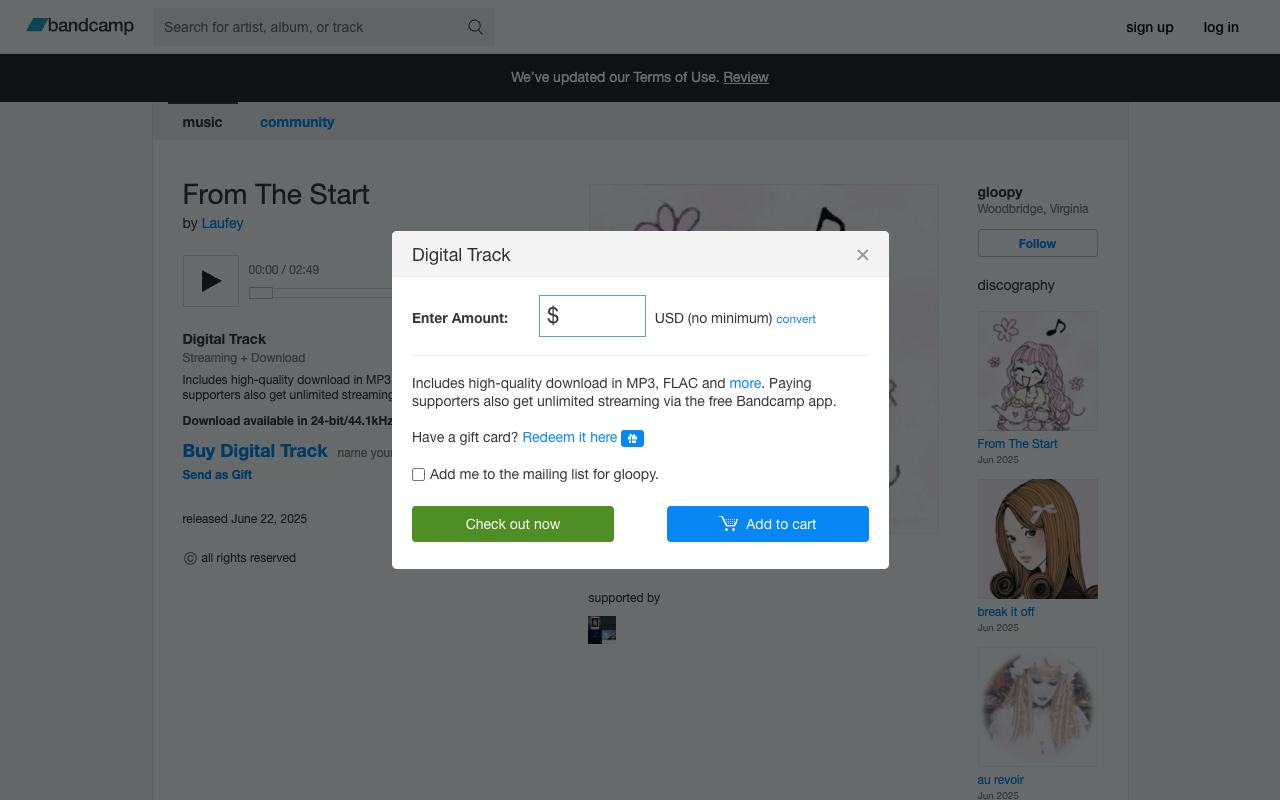
Price input appears. Claude knows what to do next.
Iteration 3:
# Navigate, click buy, fill price, add to cart
await page.goto("https://gloopy1.bandcamp.com/track/from-the-start")
await page.click("button:has-text('Buy Digital Track')")
await page.fill("#userPrice", "2.00")
await page.click("button:has-text('Add to cart')")
await page.screenshot(path="debug_3_after_cart.png")
with open("debug_3_after_cart.html", "w") as f:
f.write(await page.content())
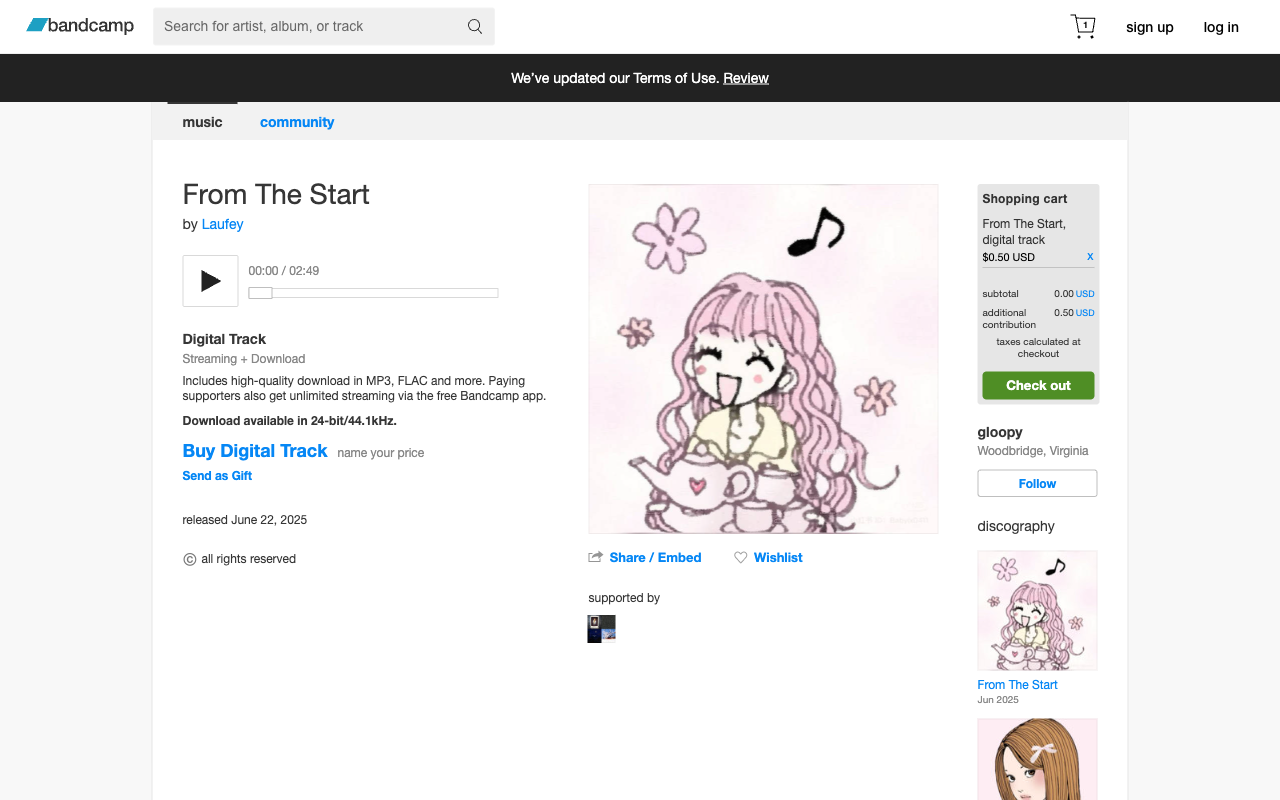
Item's in the cart. Claude keeps building toward checkout.
This goes on—checkout, PayPal auth, purchase confirmation—until Claude sees the download link. Success.
The final script runs without any AI. Just pure automation, built by showing Claude what to click at each step.
This is a totally different way to write a scraper. Overall it saved me a lot of time (and I enjoyed the process).
Example 3: Self-Improving Synthetic Data Pipeline¶
I wanted to synthesize data to test our product. The twist: I need to evaluate the evaluator. Are my fake users realistic? Diverse? Actually testing the right things?
My self-verification pipeline:
- Generate conversations: Claude runs a script that creates 20 synthetic user-agent conversations
- Evaluate quality: Claude writes another script that programmatically evaluates these conversations against defined criteria (stored in MLflow/Databricks)
- Generate reports: Produces markdown reports with quality metrics and progress tracking
Claude reads these reports, plans improvements, implements changes, evaluates again. Each iteration gets better:
📊 Initial Report - June 30, 22:48 (Realism: 0%, Coverage: 0%, Tool diversity: 0)
Example Synthetic Data Analysis Report (Initial)
Generated: 2025-06-30T22:48:16.485474 Traces Analyzed: 10
Executive Summary
⚠️ Good diversity - All 10 synthetic conversations were unique
⚠️ Zero errors - Quality checks passed 100%
❌ Conversations unrealistic - Users ask questions like robots
The pipeline works but needs improvement. Conversations are diverse but don't feel human yet.
Initial Assessment
✅ What's working:
- Diversity at 100%
- Quality at 100%
🔴 Major issues:
- Conversations feel robotic (Realism: 0%)
- Limited feature coverage (Coverage: 0%)
- No tool usage (Tool diversity: 0)
- Conversation endings abrupt (0%)
Score Summary
| Metric | Score |
|---|---|
| Diversity Score | 1.00 |
| Quality Score | 1.00 |
| Realism Score | 0.00 |
| Ending Realism Score | 0.00 |
| Coverage Score | 0.00 |
🔄 Iterate
After seeing this report, I ask Claude to come up with a plan to fix the issues. Claude analyzes the metrics and proposes specific changes—maybe adding natural language patterns, expanding test scenarios, or introducing tool usage. We implement the plan, check the changes into GitHub, run the pipeline again, and generate a new report:
📊 Improved Report - June 30, 22:55 (Realism: 100% ✅, Coverage: 67% ⬆️, Tool diversity: 19 ⬆️)
Example Synthetic Data Analysis Report
Generated: 2025-06-30T22:55:38.621661 Traces Analyzed: 14
Executive Summary
✨ Perfect diversity - All 14 synthetic conversations were completely unique
✨ Zero errors - Quality checks passed 100%
✨ No repetition - Each synthetic user asked different questions
The pipeline is working! It's generating realistic, diverse conversations that actually test different aspects of the agent.
Comparison with Previous Report
Comparing with report from 2025-06-30T22:48:16.485474
✅ What got better:
- Conversations feel real now (Realism: 0→100%)
- Better feature coverage (Coverage: 0→67%)
- Using more tools (Tool diversity: 0→19)
🔷 Still perfect:
- Diversity stays at 100%
- Quality stays at 100%
🔴 Still needs work:
- Conversation endings still abrupt (0%)
Score Changes Summary
| Metric | Previous | Current | Change | % Change |
|---|---|---|---|---|
| Diversity Score | 1.00 | 1.00 | 0.00 | 0.0% |
| Quality Score | 1.00 | 1.00 | 0.00 | 0.0% |
| Realism Score | 0.00 | 1.00 | +1.00 | +0.0% |
| Ending Realism Score | 0.00 | 0.00 | 0.00 | 0.0% |
| Coverage Score | 0.00 | 0.67 | +0.67 | +0.0% |
Conclusion¶
We're living through a paradigm shift. The old way: write code, check it works, fix bugs, repeat. The new way: teach AI to verify its own work, then scale horizontally.
Self-verification loops aren't just a nice-to-have—they're the difference between AI as a typing assistant and AI as a team of engineers. I find these loops everywhere now:
- Claude writes SQL → executes it against real data → sees the results
- Claude changes an API → frontend types auto-update → Claude tests the endpoints
- Claude deploys → watches /logz for errors → fixes and redeploys
Once you internalize this pattern, you can't unsee it. Every manual check becomes an opportunity for automation. Every "let me test this" becomes "Claude, test this and show me the results."
We should build our software to enable these loops for others too. Every deployment should expose logs at a predictable URL. Every operation should return structured, parseable results. When you ship software that AI can self-verify against, you're not just building a product—you're building something others can build on.
The tools that enable this—fast feedback loops, rich types, good observability—were always best practices. Now they're table stakes. Because when your AI can verify its own work, you stop being a debugger and start being a builder.
This changes everything about how we build. These systems aren't perfect—they make mistakes. But I've realized the real challenge isn't AI fallibility; it's that we rarely know what we're building until we start. Requirements emerge through iteration. With self-verification loops, I can embrace this reality. Think of a feature, ask Claude to implement it, and while it's building and checking its own work, I have the mental space to discover what should come next. The flow state becomes sustainable.
The musicians can finally hear when they're off-key. Time to write the symphony.